A Quick recap:
- From Part 1 we saw that you can organise logical tables in a normalised fashion, and in a simple model the SQL will work without errors. The use of a normalised model in the Data warehouse is not something that you would normally see being advocated by the Warehouse experts, and yet we face pressure from clients to reduce the development time and complexity of the warehouse, which can lead to so called sub-optimal performance.
- From Part 2 we saw that organising the logical model into a proper star led to the most efficient SQL being generated. This SQL will enable STAR Transformation to work in an Oracle DB. We also see that for this to work you need all the relevant foreign keys on the fact.
In this section we are going to explore the Hybrid design. This design is common to most implementations that I have seen.
The logical model is designed as a star. However, the physical model is a Snowflake.
The LOGICAL MODEL.

I have only shown one dimension here for simplicity, but there can be several dimensions attached to the fact.

Here I have shown three logical tables to demonstrate the different methods for the Logical Table Sources (LTS)
If you look at the Logical table sources in W_PERSON_D, you will see that I have three set up, with the LTS name being the same as the underlying Physical table:

In this example each one contains just one Physical Table. The first one contains just the HYBRID_PERSON_D:

And the column mapping is...

If we look at the column mapping for PERSON_DX

We can see that only those columns that exist in the physical table are matched to the Logical Columns. This will force the engine to use this LTS if any of these fields are used. Also note that I have mapped the ROW_WID field to the DX field that contains the Person Row WID.
Now let’s look at a report being run using this Logical Dimension.

No errors and the SQL does the magic of combining the separate Logical Sources
select T5260."FULL_NAME" as c1,
T5303."ACCNT_WID" as c2,
T5303."BRICK_WID" as c3,
sum(T5274."BLAH_VALUE") as c4
from
"W_XREF_PERSON_M" T5303,
"W_PERSON_D" T5260,
"W_PERSON_F" T5274
where ( T5260."ROW_WID" = T5274."CONTACT_WID"
and T5260."ROW_WID" = T5303."CONTACT_WID" )
group by T5260."FULL_NAME", T5303."ACCNT_WID", T5303."BRICK_WID"
And if I just want to query against the Name:
T5303."ACCNT_WID" as c2,
T5303."BRICK_WID" as c3,
sum(T5274."BLAH_VALUE") as c4
from
"W_XREF_PERSON_M" T5303,
"W_PERSON_D" T5260,
"W_PERSON_F" T5274
where ( T5260."ROW_WID" = T5274."CONTACT_WID"
and T5260."ROW_WID" = T5303."CONTACT_WID" )
group by T5260."FULL_NAME", T5303."ACCNT_WID", T5303."BRICK_WID"
And if I just want to query against the Name:

Then the SQL shows that only the relevant tables are queried:
select T5260.`FST_NAME` as c1,
sum(T5274.`BLAH_VALUE`) as c2
from `W_PERSON_D` T5260, `W_PERSON_F` T5274
where ( T5260.`ROW_WID` = T5274.`CONTACT_WID` )
group by T5260.`FST_NAME`
(unfortunately I am using Access for my sample database and Access does NOT support comments in SQL, otherwise you would see which LTS has been used)
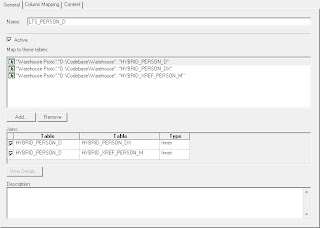
Now let’s look at Person V2
Here we can see that I have added just one LTS

(unfortunately I am using Access for my sample database and Access does NOT support comments in SQL, otherwise you would see which LTS has been used)
Now let’s look at Person V2
Here we can see that I have added just one LTS

But that LTS has three physical sources,

And if we run a request:
(the same one as above)
(the same one as above)

Then this time the SQL is as follows:
select T5260.`FST_NAME` as c1, sum(T5274.`BLAH_VALUE`) as c2
from `W_PERSON_D` T5260, `W_XREF_PERSON_M` T5303, `W_PERSON_F` T5274
where ( T5260.`ROW_WID` = T5274.`CONTACT_WID`
and T5260.`ROW_WID` = T5303.`CONTACT_WID` )
group by T5260.`FST_NAME`
As you can see W_PERSON_D and W_XREF_PERSON_M are included in the SQL but not W_PERSON_DX? Why? W_XREF_PERSON_M is not even used in the request columns and it does not help the SQL to answer the request!
We know that PERSON_DX is joined to PERSON_D using a physical foreign key, whereas PERSON_M is using a logical key. So let experiment with the keys to see what happens.
I changed the join between PERSON_D and PERSON_DX to a physical join, not a physical foreign key, and re-ran the report, which resulted in the following SQL.
As you can see W_PERSON_D and W_XREF_PERSON_M are included in the SQL but not W_PERSON_DX? Why? W_XREF_PERSON_M is not even used in the request columns and it does not help the SQL to answer the request!
We know that PERSON_DX is joined to PERSON_D using a physical foreign key, whereas PERSON_M is using a logical key. So let experiment with the keys to see what happens.
I changed the join between PERSON_D and PERSON_DX to a physical join, not a physical foreign key, and re-ran the report, which resulted in the following SQL.
select T5260.`FST_NAME` as c1, sum(T5274.`BLAH_VALUE`) as c2
from `W_PERSON_D` T5260, `W_PERSON_DX` T5267, `W_XREF_PERSON_M` T5303, `W_PERSON_F` T5274
where ( T5260.`ROW_WID` = T5267.`ROW_WID` and T5260.`ROW_WID` = T5274.`CONTACT_WID` and T5260.`ROW_WID` = T5303.`CONTACT_WID` )
Group by T5260.`FST_NAME`
This time the PERSON_DX tables was added into the SQL even though it is not used in the request.
Now let’s have a look at a third way. This combines the two methods above of creating the LTS’s.
Here I have created the dimension with 3 LTS
This time the PERSON_DX tables was added into the SQL even though it is not used in the request.
Now let’s have a look at a third way. This combines the two methods above of creating the LTS’s.
Here I have created the dimension with 3 LTS

Each one contains the W_PERSON_D table. The first is on it’s own, the second contains both Person D and DX, the third Person D and XREF M table. The choice for the developer with this set-up is what fields to map where. Take ‘First Name’, do you map this to just the first LTS or all three?
If I map it to all three then run the following report

I get the following SQL
select T5260.`FST_NAME` as c1, T5267.`ATTRIB_11` as c2, sum(T5274.`BLAH_VALUE`) as c3
from `W_PERSON_D` T5260, `W_PERSON_DX` T5267, `W_PERSON_F` T5274
where ( T5260.`ROW_WID` = T5267.`ROW_WID` and T5260.`ROW_WID` = T5274.`CONTACT_WID` )
group by T5260.`FST_NAME`, T5267.`ATTRIB_11`
order by 1, 2
One piece of SQL gets all the answers
Now if I map ‘First name’ only to the HYBRID_PERSON_D LTS and re-run the report, I get
One piece of SQL gets all the answers
Now if I map ‘First name’ only to the HYBRID_PERSON_D LTS and re-run the report, I get
select T5260.`FST_NAME` as c1, T5267.`ATTRIB_11` as c2, sum(T5274.`BLAH_VALUE`) as c3
from `W_PERSON_D` T5260, `W_PERSON_DX` T5267, `W_PERSON_F` T5274
where ( T5260.`ROW_WID` = T5267.`ROW_WID` and T5260.`ROW_WID` = T5274.`CONTACT_WID` )
group by T5260.`FST_NAME`, T5267.`ATTRIB_11`
order by 1, 2
ITS THE SAME! The Analytics engine just puts together the SQL it needs, irrespective of your chosen method of LTS.
ITS THE SAME! The Analytics engine just puts together the SQL it needs, irrespective of your chosen method of LTS.
Summary
So what is going on? In the example model we have seen that
it does not matter what logical or physical model is used, OBIEE still works.
It does not matter how you set-up your logical table sources, OBIEE will put them together in a small query to get the results.
If you use a physical join, then OBIEE will always use the joined to table in the query, even if it’s not necessary.
If you use a Physical Foreign Key, and have the joined table in an LTS, it will only use the joined table when it is needed in the results.
So does design Matter?
Given the evidence so far, it would appear that you can do without a specific design. A complete beginner can do what they like and OBIEE will deal with it. So beginners can get away with building however they choose. If your dataset is small then performance will not be an issue, and if speed of response is bad then designers can always blame the network/db/server/web! When a project starts out, or is just a prototype then you do not need to consider the future addition of facts and dimensions so who cares what the technical stuff looks like. If you want to impress the client by saying you can install in 3 weeks then you had better forget design cause this takes longer, and once you have wowed the client you will get further work and no-one else will see your build (I know who you are!).
If a client has gone for the cheapest option, ie offshore, then they do not care about the quality of the work done, so build it however you like – they will never know.
But, I care what work I produce, and I normally work on very large databases which will not forgive poorly written SQL. If you have an Oracle environment then you want to maximise the use of Star transformations. For any large system you will want to take advantage if summaries. In my simple model I have used tables which join using the Person unique code. I have also not used any aggregations. There are no Hierarchies. There are no Level based measures. There are no visibility filters in place.
All of these features are what make OBIEE a useful tool for the analysis of large amounts of data, by end users with no need to fully understand SQL. Without these features, Drilling through data levels to find the specific issues would take too long. Summary reports would be too slow and users would revert back to Access, Excel and SAS. In fact, if your users still insist on using Excel or Access for a large amount of their analysis then your installation of OBIEE DESIGN is failing (You cannot totally remove Excel, in fact you should be encouraging some integration with OBIEE).
But, I care what work I produce, and I normally work on very large databases which will not forgive poorly written SQL. If you have an Oracle environment then you want to maximise the use of Star transformations. For any large system you will want to take advantage if summaries. In my simple model I have used tables which join using the Person unique code. I have also not used any aggregations. There are no Hierarchies. There are no Level based measures. There are no visibility filters in place.
All of these features are what make OBIEE a useful tool for the analysis of large amounts of data, by end users with no need to fully understand SQL. Without these features, Drilling through data levels to find the specific issues would take too long. Summary reports would be too slow and users would revert back to Access, Excel and SAS. In fact, if your users still insist on using Excel or Access for a large amount of their analysis then your installation of OBIEE DESIGN is failing (You cannot totally remove Excel, in fact you should be encouraging some integration with OBIEE).
In the real world the joins in a dimension can be numerous, not use the Dimension keys and sometimes involve complex joins. The joining of tables in a one-to-many relationship can result in multiple results for a single dimension e.g. Person, which when used with a fact causes duplication of facts. If you have multiple Logical Table Sources then you have to be sure they will work together. If the user were to choose a field from each source do they get an error? If so why?
How do you incorporate Dimension attributes, for example a Contact could be a Doctor who works at a particular Hospital, but later changes to another Hospital. Do you store the doctors hospital in the facts where contact exists (true Star Schema style) or in the Contact dimension, or linking from Contact to Account (Snowflake) or in an SCD? If you use a pure normalised model then this is not a problem, or is it? How do you reflect history? Do all the patients the doctor has treated over time get added up in his new hospital?
So my point is, yes you can do quick and dirty, and you can use normalised schemas or snowflakes or Pure Stars in OBIEE. But please do so knowing the consequences, and have good reasons for doing so. Don’t blindly follow a star schema for small implementations, which need minimal amounts of ETL. Do use as pure a star as possible for very large implementations, or where multiple facts share common dimensions.



{kind=link}
2 comments:
Hi Adrian.
Currently, I'm reading yout posts about using star or snowflake model in OBIEE. I also try to do some star/snowflake tests to find some errors or irregularities of using snowflake. But, so far, I cannot find any of them.
So one question...
You wrote:
...
We know that PERSON_DX is joined to PERSON_D using a physical foreign key, whereas PERSON_M is using a logical key.
...
I supose that you have (in your physical layer) relationship:
PERSON_DX -- join1 --< PERSON_D >-- join2 -- PERSON_M
Did you mean that you have join1 like
physical foreign key in physical layer and join2 like
physical join in physical layer (you wrote logical join, so I assume that you have used complex join in physical join to join these two tables)?
If this is correct, whay would you use logical join (complex join, or physical join in physical layer) to join PERSON_M to PERSON_D?
Regards.
Goran.
http://108obiee.blogspot.com
Hi Goran
Yes you are correct to say complex join (as per the OBIEE terms). Complex joins are used where no foreign key truely exists, although you can tell OBIEE there is a foreign key even if it's not true.
The complex join is used is this sample scenario to join a tbal ewith Many Person records to the Person dimension. The PERSON_M table is not a fact, but shows multiple records for a person, for example Contact Categories. The alternative pure star model would require a fact record for each instance of contact category, and would require measures to be split equally over the number of records. Either solution is not ideal, but the Many to Dimension link is the easiest to implement.
A.
Post a Comment