Bit of a techie one today, a short introduction to instanceconfig.xml.
Instanceconfig.xml (we’ll call it IC) is a configuration file for the Analytics web. It is a replacement for using the registry. You could use the registry but there’s little point, and you probably won’t have access rights anyway.
The IC file sits in C:\SiebelAnalyticsData\Web\config and is installed with the application. The basic installation provides a simple set of instructions to the Web component (see below), which one can add to or change.
The basic module looks like this, (i have removed the lead<)
?xml version="1.0" encoding="utf-8"?>
webconfig>
serverinstance>
dsn>
AnalyticsWeb
/dsn>
javahome>
C:/j2sdk1.4.2_08
/javahome>
catalogpath>
C:/SiebelAnalyticsData/web/catalog/Majendi_dev.webcat
/catalogpath>
catalogmaxautosaves>
10
/catalogmaxautosaves>
alerts>
scheduleserver>
UK_SRV_123
/scheduleserver>
/alerts>
/serverinstance>
/webconfig>
Notice the opening tag, ?xml version="1.0" encoding="utf-8"?>
. This will be present in all the xml files in Analytics. Make sure you don’t place anything before this, including spaces (As I found out the hard way).
The javahome>
tag points to your installation of Java SDK. Make sure there are no spaces in the path or this will fail.
The catalogpath> is easy to understand, and here I have renamed the catalog to Majendi_dev.webcat. If you put a name of a file that does not exist in this key then Analytics will create it for you.
The dsn> tag provides the name for ODBC connections.
You may notice that there is a sub-section for Alerts, which, in this case, tells the web server where to find the scheduling server.
There is no simple source or reference to tell you what other tags may be added, and what their settings are (I’ll try to put one in by book), but you can glean hints from other peoples SR’s and from bookshelf!
If you add a views tag then you can customise the number of rows. Try adding the following
resultrowlimit>12000
/resultrowlimit>
This a basic one, it increase the maximum number of rows that Analytics will return (the default setting is 10,000)
Other more complex ones can change small behaviours within the system, for example,
pivotview>
maxvisiblepages>
1000
/maxvisiblepages>
/pivotview>.
This set could be useful
views>
table>
defaultrowsdisplayed>200
/defaultrowsdisplayed>
defaultrowsdisplayedindelivery>250
/defaultrowsdisplayedindelivery>
defaultrowsdisplayedindownload>1250
/defaultrowsdisplayedindownoad>
/table>
/views>
Do you want to change the default skin, easy..
!-- Default Styles -->
defaultstyle>Majendi
/defaultstyle>
defaultskin>Majendi
/defaultskin>
How giving more values in a drop down list
!-- Prompts -->
prompts>
maxdropdownvalues>20000
/maxdropdownvalues>
/prompts>
Have a good look at the bookshelf and Service Requests in SupportWeb for many more examples. If you find any undocumented ones post them here, and I’ll put them in the book.
Thursday, December 21, 2006
Wednesday, December 20, 2006
And then there were three...
ETL tools used in Oracle BI that it.
With Oracle going round buying up lots of companies they have been creating a huge potential for confusion for the integration community, including their own consultants.
We had an Oracle consultant in the other day to tune up the database performance (he was very knowledgeable by the way). He had just transferred into the new BI practice and was an expert with OWB, the in house ETL tool. When faced with Informatica he had to learn quickly, on site with us showing him how to use it. Strange really, as we licence the product from Oracle.
It’s not the consultants fault; I am led to believe that there are over 500 products being used in Oracle environments, so there are probably more than three ETL tools in the mix (there’s even talk of ETL free warehouses).
But what should customers use? What should we be advising customers starting a new BI project? What will Siebel 8 use at it’s core?
Over the past year we have had lots of information and rumours coming from user groups, press releases and the consultant word of mouth. Most of what I have heard either conflicts with other messages or just doesn’t make any sense. An example is that there is talk of removing the DAC (a very useful tool btw), and replacing with an Informatica tool, but that Informatica is not their preferred ETL tool.
Over the next 3-6 months I’ll be advising clients on the technology choices they have, and when choosing Oracle, the different flavours. I’ll also be recruiting more staff and training others on the appropriate software tools. Without clear open communication from Oracle these tasks are near impossible.
I hope that we can get a better idea of where things are going as soon as possible.
With Oracle going round buying up lots of companies they have been creating a huge potential for confusion for the integration community, including their own consultants.
We had an Oracle consultant in the other day to tune up the database performance (he was very knowledgeable by the way). He had just transferred into the new BI practice and was an expert with OWB, the in house ETL tool. When faced with Informatica he had to learn quickly, on site with us showing him how to use it. Strange really, as we licence the product from Oracle.
It’s not the consultants fault; I am led to believe that there are over 500 products being used in Oracle environments, so there are probably more than three ETL tools in the mix (there’s even talk of ETL free warehouses).
But what should customers use? What should we be advising customers starting a new BI project? What will Siebel 8 use at it’s core?
Over the past year we have had lots of information and rumours coming from user groups, press releases and the consultant word of mouth. Most of what I have heard either conflicts with other messages or just doesn’t make any sense. An example is that there is talk of removing the DAC (a very useful tool btw), and replacing with an Informatica tool, but that Informatica is not their preferred ETL tool.
Over the next 3-6 months I’ll be advising clients on the technology choices they have, and when choosing Oracle, the different flavours. I’ll also be recruiting more staff and training others on the appropriate software tools. Without clear open communication from Oracle these tasks are near impossible.
I hope that we can get a better idea of where things are going as soon as possible.
Thursday, December 14, 2006
Self Configuring Warehouses
One of the reasons people don’t like the DAC is that it takes control over the ETL.
One of the reasons I like the DAC so much is the fact that it manages the ETL process with ease!
Not only does it run the Informatica tasks in the right order (providing you tell it the correct order!), but the DAC also runs other tasks, like SQL jobs.
Up to now the preferred method of running SQL in the warehouse or OLTP has been either directly (i.e. via TOAD or SQLPlus) or via stored procedures. But with the DAC you can run SQL directly that you keep in txt files in C:\SiebelAnalytics\DAC\CustomSQLs.
The usual application for these files is for simple update tasks, in the Oracle supplied example script it performs an insert.
insert into test_trgt (id) values (999)
One of the script files is used by the DAC on most tasks - customsql.xml. An example of the use of this file is the TRUNCATE statement that is run for a task. (On the task Edit page you have the choice of ‘Truncate Every Time’ and ‘Truncate on Full Load’)
The script looks like this
TRUNCATE TABLE %1
Where %1 is substituted for the table name(s) being truncated on that task.
Another useful script in customsql.xml is the Analyse statement
DBMS_STATS.GATHER_TABLE_STATS(ownname => '@TABLEOWNER', tabname => '%1', estimate_percent => 30, method_opt => 'FOR ALL COLUMNS SIZE AUTO',cascade => true )
This one is more detailed but should not be ignored in any Warehouse project. As an analyse runs every table (if you have set the correct parameters) then this job needs to run as quickly as possible. Look at some of the values e.g. estimate_percent => 30 part. You may want to adjust this!!
A custom warehouse
Now here’s the really useful bit.
So you have a new warehouse and you’ve been creating new tables (prefixed with WC_ of course), custom fields (prefixed X_ of course!) and new indexes. This work was done is a development database and needs to be populated into Test, Training, Production, Support, etc environments. You also have version 1, 1.1, 1.2, etc.
Take the DDL that manipulates the Database structure and place this into a sql script file in C:\SiebelAnalytics\DAC\CustomSQLs.
Create a task that runs the script.
Create an Execution Plan that has the above task as a precedent. I normally call this Execution Plan ‘Initial Warehouse Set-up’
You can now keep all of your environments up to date easily by distributing the latest version of the SQL script and running the execution plan.
Tip. Make sure that your SQL is very robust, i.e. checking for existing tables before trying to create them again.
DAC Attacked
There are rumours that the DAC is going to be replaced by Oracle with something else. Whatever they do I hope it has all the useful features of the current DAC, plus more.
Next topic – Should Oracle keep developing OWB or just try to buy Informatica??
One of the reasons I like the DAC so much is the fact that it manages the ETL process with ease!
Not only does it run the Informatica tasks in the right order (providing you tell it the correct order!), but the DAC also runs other tasks, like SQL jobs.
Up to now the preferred method of running SQL in the warehouse or OLTP has been either directly (i.e. via TOAD or SQLPlus) or via stored procedures. But with the DAC you can run SQL directly that you keep in txt files in C:\SiebelAnalytics\DAC\CustomSQLs.
The usual application for these files is for simple update tasks, in the Oracle supplied example script it performs an insert.
insert into test_trgt (id) values (999)
One of the script files is used by the DAC on most tasks - customsql.xml. An example of the use of this file is the TRUNCATE statement that is run for a task. (On the task Edit page you have the choice of ‘Truncate Every Time’ and ‘Truncate on Full Load’)
The script looks like this
TRUNCATE TABLE %1
Where %1 is substituted for the table name(s) being truncated on that task.
Another useful script in customsql.xml is the Analyse statement
DBMS_STATS.GATHER_TABLE_STATS(ownname => '@TABLEOWNER', tabname => '%1', estimate_percent => 30, method_opt => 'FOR ALL COLUMNS SIZE AUTO',cascade => true )
This one is more detailed but should not be ignored in any Warehouse project. As an analyse runs every table (if you have set the correct parameters) then this job needs to run as quickly as possible. Look at some of the values e.g. estimate_percent => 30 part. You may want to adjust this!!
A custom warehouse
Now here’s the really useful bit.
So you have a new warehouse and you’ve been creating new tables (prefixed with WC_ of course), custom fields (prefixed X_ of course!) and new indexes. This work was done is a development database and needs to be populated into Test, Training, Production, Support, etc environments. You also have version 1, 1.1, 1.2, etc.
Take the DDL that manipulates the Database structure and place this into a sql script file in C:\SiebelAnalytics\DAC\CustomSQLs.
Create a task that runs the script.
Create an Execution Plan that has the above task as a precedent. I normally call this Execution Plan ‘Initial Warehouse Set-up’
You can now keep all of your environments up to date easily by distributing the latest version of the SQL script and running the execution plan.
Tip. Make sure that your SQL is very robust, i.e. checking for existing tables before trying to create them again.
DAC Attacked
There are rumours that the DAC is going to be replaced by Oracle with something else. Whatever they do I hope it has all the useful features of the current DAC, plus more.
Next topic – Should Oracle keep developing OWB or just try to buy Informatica??
Monday, December 11, 2006
Two weeks to go
With only two weeks to go we're getting very nervous.
This has nothing to do with UAT (Which is actually going very well), but all to do with this years skiing holiday!
We're off to La Plagne with the kids over xmas. There's a webcam service that was showing lots of grass last week and no snow. Happily there was a light downfall over the weekend, but the tempurature is due to rise so I bet it all melts away.
I'll be keeping my eye on the forecast below and praying for snow
Fingers crossed eh?
This has nothing to do with UAT (Which is actually going very well), but all to do with this years skiing holiday!
We're off to La Plagne with the kids over xmas. There's a webcam service that was showing lots of grass last week and no snow. Happily there was a light downfall over the weekend, but the tempurature is due to rise so I bet it all melts away.
I'll be keeping my eye on the forecast below and praying for snow
Fingers crossed eh?
Thursday, November 30, 2006
Sorted!
An easy and quick tip to sort out the order of time.
When the gods invented time they were not considering the Manager running his analytics reports!
It’s a simple question that the manager asks; Give me sales figures by month.
The answer should look like this
January 10
February 11
March 13
April 13
May 15
June 19
July 22
August 35
September 22
October 12
November 11
December 10
But we ‘sorted’ by month and here’s the results L
April 13
August 35
December 10
February 11
January 10
July 22
June 19
March 13
May 15
November 11
October 12
September 22
Which is perfectly understandable really but not very readable.
So how do we get the proper results?
In the source table (normally W_DAY_D) where the month names are held there is normally a month number too (mth_num). Obviously this loops from 1 to 12 for each year. We will need the field containing the month number to be included as a logical column in the logical table where the month name is sourced from in the report. You’ll probably call this field ‘Month Number’!.
Now edit the ‘Month Name’ logical column. On the General tab there is a ‘Sort by’ box. Use the ‘Set’ button to find and select the ‘Month Number’ field.
Now whenever analytics has a query that include the Month Name field it will automatically add the Month Number field and add an ORDER BY month_number clause.
You must be careful when adding the sort functionality into a logical column. The field used must be at the same ‘level’ (for example, you cannot use date as the sort order for a month).
The technique is useful for Day Names too (using Day of Week Number) and could even be used for non time related data (e.g. Brand names have to be in a certain order).
When the gods invented time they were not considering the Manager running his analytics reports!
It’s a simple question that the manager asks; Give me sales figures by month.
The answer should look like this
January 10
February 11
March 13
April 13
May 15
June 19
July 22
August 35
September 22
October 12
November 11
December 10
But we ‘sorted’ by month and here’s the results L
April 13
August 35
December 10
February 11
January 10
July 22
June 19
March 13
May 15
November 11
October 12
September 22
Which is perfectly understandable really but not very readable.
So how do we get the proper results?
In the source table (normally W_DAY_D) where the month names are held there is normally a month number too (mth_num). Obviously this loops from 1 to 12 for each year. We will need the field containing the month number to be included as a logical column in the logical table where the month name is sourced from in the report. You’ll probably call this field ‘Month Number’!.
Now edit the ‘Month Name’ logical column. On the General tab there is a ‘Sort by’ box. Use the ‘Set’ button to find and select the ‘Month Number’ field.
Now whenever analytics has a query that include the Month Name field it will automatically add the Month Number field and add an ORDER BY month_number clause.
You must be careful when adding the sort functionality into a logical column. The field used must be at the same ‘level’ (for example, you cannot use date as the sort order for a month).
The technique is useful for Day Names too (using Day of Week Number) and could even be used for non time related data (e.g. Brand names have to be in a certain order).
Thursday, November 16, 2006
Yuk
I've been ill!
Sorry about being quiet for so long but I've either been busy on a project (or several projects more like), or ill in bed.
I even missed interviewing some people who I'd like to join Majendi, so I hope they forgive me.
Anyway, I'm back to rude health (as much as you can be at 37) and raring for the next blog. Any suggestios as to what i should write about?
Adrian
Sorry about being quiet for so long but I've either been busy on a project (or several projects more like), or ill in bed.
I even missed interviewing some people who I'd like to join Majendi, so I hope they forgive me.
Anyway, I'm back to rude health (as much as you can be at 37) and raring for the next blog. Any suggestios as to what i should write about?
Adrian
Friday, October 06, 2006
Navigation
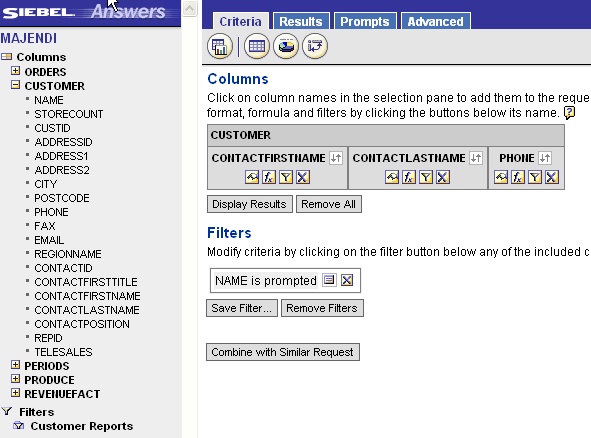
Another popular topic on the message boards of late has been navigation between reports on Dashboards. Most commonly this involves guiding the user to another report/dashboard from a particular value displayed in the results of the initial report, for example, at a financial quarter end you may wish to drill down and see sales figures for the best or worst performers in a ranked list. As long as there is a common value that you include in the two reports then this simple method can be applied to any two reports. In our example we use a list of customers and link to there contact details.
The only complicated part of this is that you need to plan your report hierarchy first as the reports need to be created starting with the last (bottom of the drill down pile) first. The reason for this will be clear in a moment, as my example only links two reports I will start with the second. I need to telephone the client so all I need is their contact name and number, as I want to see these individually according to which customer I select from the list I will need the contacts report to be filtered by the value I choose in the first report, in this sample data the common field is the Customer.Name, granted in real life this is more likely be an ID, this field needs to be filtered using an ‘Is Prompted’ filter type.
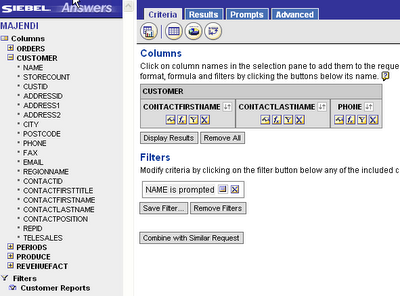
The sharp eyed amongst you will have noticed that the Customer.Name column is used in the filter but is not in the report, this keeps things tidier, we don’t need the name as we will have selected that to get to this report. To add a filtered column in this way hold down the Shift key and click the column name in the usual way, the Create/Edit Filter dialogue will open automatically. Save the report and create the parent report that will be presented to users first.
For simplicity the report has only two columns, NAME and REGIONNAME from the Customer table, NAME is the column we have used for the filter prompt in our child report so that is the value will use to navigate from. In the column properties for NAME we use the Column Format tab and the Value Interaction property, define the interaction Type as Navigate and then use the Browse button to select the Contacts report we created earlier.
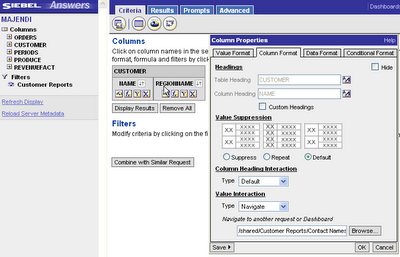
If we now add this report to a dashboard, the child report remains linked and will be displayed on a new page within the same dashboard. Alternatively, you may wish to bring to the users attention other details about the customer at the same time, probably the easiest way to do this is to add the child report to a new dashboard, in this instance I shall call it customer detail, add any number of reports to this dashboard with ‘Is Prompted’ filters and they will all display detail for this customer.
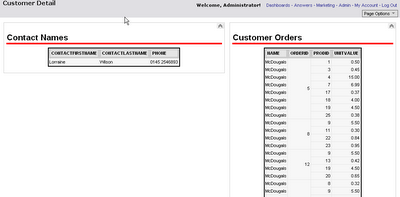
Next time I'll write up on how we make a dynamic heirarchy that changes depending upon the user who logs in.
The only complicated part of this is that you need to plan your report hierarchy first as the reports need to be created starting with the last (bottom of the drill down pile) first. The reason for this will be clear in a moment, as my example only links two reports I will start with the second. I need to telephone the client so all I need is their contact name and number, as I want to see these individually according to which customer I select from the list I will need the contacts report to be filtered by the value I choose in the first report, in this sample data the common field is the Customer.Name, granted in real life this is more likely be an ID, this field needs to be filtered using an ‘Is Prompted’ filter type.
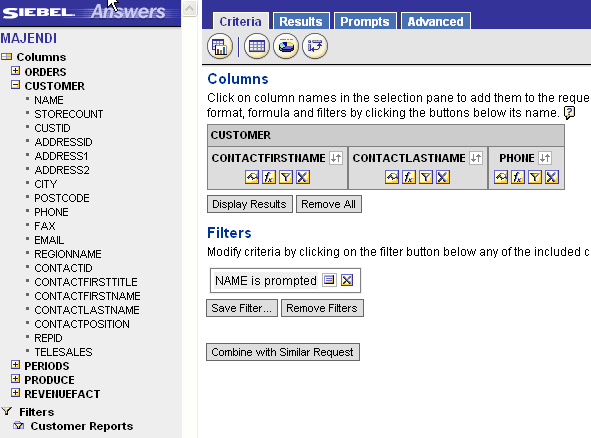
The sharp eyed amongst you will have noticed that the Customer.Name column is used in the filter but is not in the report, this keeps things tidier, we don’t need the name as we will have selected that to get to this report. To add a filtered column in this way hold down the Shift key and click the column name in the usual way, the Create/Edit Filter dialogue will open automatically. Save the report and create the parent report that will be presented to users first.
For simplicity the report has only two columns, NAME and REGIONNAME from the Customer table, NAME is the column we have used for the filter prompt in our child report so that is the value will use to navigate from. In the column properties for NAME we use the Column Format tab and the Value Interaction property, define the interaction Type as Navigate and then use the Browse button to select the Contacts report we created earlier.

If we now add this report to a dashboard, the child report remains linked and will be displayed on a new page within the same dashboard. Alternatively, you may wish to bring to the users attention other details about the customer at the same time, probably the easiest way to do this is to add the child report to a new dashboard, in this instance I shall call it customer detail, add any number of reports to this dashboard with ‘Is Prompted’ filters and they will all display detail for this customer.

Next time I'll write up on how we make a dynamic heirarchy that changes depending upon the user who logs in.
Friday, September 22, 2006
All about the Cache
Here a thing that will makeyour reports run faster!
Introduction to Cache
Decision support queries sometimes require large amounts of database processing. If you reduce the amount of database querying then you can speed up the time to produce reports. In an Analytics system the way to reduce database accesses is to create a ‘Cache’ of data on the same machine as the Analytics engine. The Siebel Analytics Server can save the results of a query in cache files and then reuse those results later when a similar query is requested. We refer to this as ‘query cache’. Using query cache, the cost of database processing only needs to be paid once for a query, not every time the query is run.
The query cache allows the Analytics Server to satisfy many subsequent query requests without having to access the back-end databases. This reduction in communication costs can dramatically decrease query response time.
However, as updates occur on the back-end databases (due to an ETL run), the query cache entries do not reflect the latest data in the warehouse; they become ‘stale’. Therefore, Siebel Analytics administrators need either to enable a method of updating the cash on a rolling basis, or purge it of old data and refresh it to a set schedule.
Caching may be considered to have small cost in terms of disk space to store the cache, and a small number of I/O transactions on the server but the this should be easily outweighed by the improvement in query response times. Caching does require some on going management in terms of limiting the cache size and ensuring the data is refreshed, but both these tasks can be controlled automatically.
Not all queries are suitable for cache use. A simple list of all accounts would not be a good dataset to cache as the cache file would be too large.
The Plan
1. Start with Cache enabled
Caching is proven to be generally beneficial so there is nothing to be gained from not enabling some form of caching from the outset. (exception noted above)
2. Develop a cache updating method.
Analytics has various methods to manage the cache generation and deletion.
3. Monitor query code to spot potential for improvement to the cache.
Check for slow running queries on an ongoing basis.
Cache Testing
It is prudent to test your reports to ensure that they do benefit from the cached data.
1. Test the response times on queries using cache
2. Test the response times on queries not using cache
Cache Methods
This section describes the available methods of ensuring the data in the cache is kept current.
For the cache to be effective as a means or of performance enhancement it needs to be populated with relevant data quickly, relying on this data being built up as a result of users queries is not practical where the data will be updated frequently. To speed population a process known as seeding can be implemented, this involves running carefully designed queries to populate the cache with the required data. This can be done in a number of ways but the most efficient is to build this functionality into the ETL process.
One of the costs, or disadvantages of caching is the potential for data latency, or a ‘stale’ cache, this occurs when the data in the cache is not purged after the data warehouse has been updated, there are several options available to deal with this.
Possible Methods
a. No Cache
b. Polling table
c. Caching enabled at table level
d. Manual Cache Management
a. No Cache - If no cache is used then every request for data will generate a new SQL query that will be applied to the SRMW, this increase network traffic, hugely increases the demands on the server and affects productivity. The speed at which the results are returned is governed by the speed of the database and the network, and the ability of the Analytics server to compute the parameters of the query.
b. Polling table - Data can be refreshed using an Event Table. This is a table in the database which is populated with an entry recording the details of a table when that table is updated by the ETL process, the Analytics Server polls the table and purges data from the cache if a table has been updated. This is useful where incremental ETL processes are run during the day, for instance to update sales data, the frequency with which the Analytics Server checks the polling table can be set to coincide with that of the ETL so data from the more frequently updated tables is purged from the cache more often to avoid out of date results to queries. Where incremental ETL is run once a day or overnight for instance, this approach is arguably less beneficial. The frequency with which the Analytics Server polls the event table is set in the Analytics Administration tool, Tools>Utilities>Siebel Event Tables. N.B The parameters for the Event table contain table names only and cannot contain an alias, when the data for a table is purged data from an alias of that table is not, this can lead to misleading results and an alterative purging strategy must be found for the alias.
c. Table Level - In it’s simplest form, caching can be enabled table by table within the data warehouse, by default all tables have caching enabled and the persistence time, the time the data is left in the cache, is infinite. To achieve the best combination of performance improvement whilst limiting disk space used by the cache, tables that are rarely queried can be deselected from this process, performance can be further enhanced by altering the persistence time to coincide with incremental ETL processes as with method b. The two methods can also be used in conjunction with each other.
It is still important to purge the cache otherwise you can be querying yesterday’s data, even though an ETL was run overnight.
d. Manual Management – A cache manager is available from within the repository when you are connected in online mode. To access the Cache Manager select Tools\ Manage\ Cache. Note that this option is greyed out unless you have enabled caching in the NQSConfig.ini file. Manual cache management involves the purging of cache physically by a user. It is not suitable for day to day operations, but can be handy during testing.
Purging Options
Invoking ODBC Extension Functions
The following ODBC functions affect cache entries associated with the repository specified by the ODBC connection. You can call these functions using the nqcmd.exe command-line executable.
The syntax of the call will be as follows:
nqcmd -d "Analytics Web" –u administrator –p sadmin –s purge.txt
Where purge.txt contains the call (for example, call SAPurgeAllCache()).
SAPurgeCacheByQuery. Purges a cache entry that exactly matches a specified query.
The following call programmatically purges the cache entry associated with this query:
Call SAPurgeCacheByQuery(‘select lastname, firstname from employee where salary >
100000’ );
SAPurgeCacheByTable. Purges all cache entries associated with a specified physical table
name (fully qualified) for the repository to which the client has connected.
This function takes up to four parameters representing the four components (database, catalog,
schema and table name proper) of a fully qualified physical table name. For example, you might have a table with the fully qualified name of DBName.CatName.SchName.TabName. To purge the cache entries associated with this table in the physical layer of the Siebel Analytics repository, execute the following call in a script:
Call SAPurgeCacheByTable( ‘DBName’, ‘CatName’, ‘SchName’, ‘TabName’ );
Wild cards are not supported by the Siebel Analytics Server for this function. Additionally,
DBName and TabName cannot be null. If either one is null, you will receive an error message.
SAPurgeAllCache. Purges all cache entries. The following is an example of this call:
Call SAPurgeAllCache();
SAPurgeCacheByDatabase. Purges all cache entries associated with a specific physical
database name. A record is returned as a result of calling any of the ODBC procedures to purge
the cache. This function takes one parameter that represents the physical database name and
the parameter cannot be null. The following is an example of this call:
Call SAPurgeCacheByDatabase( ‘DBName’ );
Siebel Analytics Scheduler
The SA Scheduler can be used for running general purpose scripts that extend the functionality of Siebel Analytics.
The script purgeSASCache is used to periodically purge all of the cache from the Siebel Analytics Server:
/////////////////////////////////////////////////////////
// purgeSASCache.js
//
// Purges the cache on SAS.
// Parameter(0) - The user name to pass in to NQCMD.
// Parameter(1) - The password for the aforementioned user.
/////////////////////////////////////////////////////////
// The full path to nqcmd.exe
var nqCmd = "D:\\SiebelAnalytics\\Bin\\nqcmd.exe";
// The data source name
var dsn = "Analytics Web";
// The user to execute the queries
var user = Parameter(0);
// The password of the aforementioned user
var pswd = Parameter(1);
// The ODBC procedure call for purging the cache
var sqlStatement = "{call SAPurgeAllCache()};";
//////////////////////////////////////////////////////////
// Returns a string from the file name
//////////////////////////////////////////////////////////
function GetOutput(fso, fileName)
{
var outStream = fso.OpenTextFile(fileName, 1);
var output = outStream.ReadAll();
outStream.Close();
return output;
}
//////////////////////////////////////////////////////////
// Get WshShell object and run nqCmd. Capture the output
// so that we can handle erroneous conditions.
var wshShell = new ActiveXObject("WScript.Shell");
// Create a temp file to input the SQL statement.
var fso = new ActiveXObject("Scripting.FileSystemObject");
var tempFolder = fso.GetSpecialFolder(2);
var tempInFileName = fso.GetTempName();
var tempOutFileName = fso.GetTempName();
tempInFileName = tempFolder + "\\" + tempInFileName;
tempOutFileName = tempFolder + "\\" + tempOutFileName;
var tempInFile = fso.CreateTextFile(tempInFileName, true);
tempInFile.WriteLine(sqlStatement);
tempInFile.Close();
try
{
// execute
var dosCmd = nqCmd + " -d \"" + dsn + "\" -u \"" + user
+ "\" -p \"" + pswd + "\" -s \"" + tempInFileName + "\"" +
" -o \"" + tempOutFileName + "\"";
wshShell.Run(dosCmd, 0, true);
var output = GetOutput(fso, tempOutFileName);
// Remove the temp files
fso.DeleteFile(tempInFileName);
if (fso.FileExists(tempOutFileName)) {
fso.DeleteFile(tempOutFileName);
}
// Check the output for any errors
if (output.indexOf("Processed: 1 queries") == -1) {
ExitCode = -1;
Message = output;
}
else if (output.indexOf("Encountered") != -1) {
ExitCode = -2;
Message = output;
}
else {
ExitCode = 0;
}
} catch (e) {
if (fso.FileExists(tempInFileName)) {
fso.DeleteFile(tempInFileName);
}
if (fso.FileExists(tempOutFileName)) {
fso.DeleteFile(tempOutFileName);
}
throw e;
}
Options for Seeding the Cache
Seeding the cache can be automated via an ODBC call in much the same way as purging.
The syntax of the call will be as follows:
nqcmd -d "Analytics Web" –u administrator –p sadmin – file.sql
Where file sql is a script containing sql select statements to populate the cache, ideally these will be a super set of the queries issued by the requests in Siebel Answers and dashboards deemed most likely to derive maximum performance gains from using the cache.
Siebel Delivers can also be used to seed the cache automatically, the advantage of this is that iBots can trigger the specific requests that are required for caching, this should carry further performance benefits.
NQSConfig.ini
The NQSConfig.ini file located in the $SiebelAnalytics\Config folder needs to be modified in order to activate and parameterise Analytics Caching. Below are settings for caching with cache tables of an expected size of approximately 250 000 records.
Parameter Value Comments
ENABLE
YES
Turns overall Caching on or off
DATA_STORAGE_PATHS
“C:\SiebelAnalyticsData\Temp\Cache 500 MB”
For optimal performance, the directories specified should be on high performance storage systems.
METADATA_FILE
"C:\SiebelAnalytics\metadata_file.dat"
The filename needs to be a fully qualified pathname with a .dat extension.
REPLACE_ALGORITHM
LRU
Currently, the only supported algorithm is LRU (Least Recently Used).
BUFFER_POOL_SIZE
20 MB
Specifies the amount of physical memory Analytics can use to store Cache files, in. More cache in memory means better response time.
MAX_ROWS_PER_CACHE_ENTRY
0
When set to 0, there is no limit to the number of rows per cache entry.
MAX_CACHE_ENTRY_SIZE
10 MB
Maximum size of a specific cache entry on the Physical drive.
POPULATE_AGGREGATE_ROLLUP_HITS
YES
Specifies whether aggregate cache files should be created. Setting this parameter to TRUE may result in better performance, but results in more entries being added to the cache.
METADATA_BACKUP_FREQUENCY_MINUTES
1440
This creates a backup file with a .bak extension. There will only ever be one of these.
Hope this helps
Introduction to Cache
Decision support queries sometimes require large amounts of database processing. If you reduce the amount of database querying then you can speed up the time to produce reports. In an Analytics system the way to reduce database accesses is to create a ‘Cache’ of data on the same machine as the Analytics engine. The Siebel Analytics Server can save the results of a query in cache files and then reuse those results later when a similar query is requested. We refer to this as ‘query cache’. Using query cache, the cost of database processing only needs to be paid once for a query, not every time the query is run.
The query cache allows the Analytics Server to satisfy many subsequent query requests without having to access the back-end databases. This reduction in communication costs can dramatically decrease query response time.
However, as updates occur on the back-end databases (due to an ETL run), the query cache entries do not reflect the latest data in the warehouse; they become ‘stale’. Therefore, Siebel Analytics administrators need either to enable a method of updating the cash on a rolling basis, or purge it of old data and refresh it to a set schedule.
Caching may be considered to have small cost in terms of disk space to store the cache, and a small number of I/O transactions on the server but the this should be easily outweighed by the improvement in query response times. Caching does require some on going management in terms of limiting the cache size and ensuring the data is refreshed, but both these tasks can be controlled automatically.
Not all queries are suitable for cache use. A simple list of all accounts would not be a good dataset to cache as the cache file would be too large.
The Plan
1. Start with Cache enabled
Caching is proven to be generally beneficial so there is nothing to be gained from not enabling some form of caching from the outset. (exception noted above)
2. Develop a cache updating method.
Analytics has various methods to manage the cache generation and deletion.
3. Monitor query code to spot potential for improvement to the cache.
Check for slow running queries on an ongoing basis.
Cache Testing
It is prudent to test your reports to ensure that they do benefit from the cached data.
1. Test the response times on queries using cache
2. Test the response times on queries not using cache
Cache Methods
This section describes the available methods of ensuring the data in the cache is kept current.
For the cache to be effective as a means or of performance enhancement it needs to be populated with relevant data quickly, relying on this data being built up as a result of users queries is not practical where the data will be updated frequently. To speed population a process known as seeding can be implemented, this involves running carefully designed queries to populate the cache with the required data. This can be done in a number of ways but the most efficient is to build this functionality into the ETL process.
One of the costs, or disadvantages of caching is the potential for data latency, or a ‘stale’ cache, this occurs when the data in the cache is not purged after the data warehouse has been updated, there are several options available to deal with this.
Possible Methods
a. No Cache
b. Polling table
c. Caching enabled at table level
d. Manual Cache Management
a. No Cache - If no cache is used then every request for data will generate a new SQL query that will be applied to the SRMW, this increase network traffic, hugely increases the demands on the server and affects productivity. The speed at which the results are returned is governed by the speed of the database and the network, and the ability of the Analytics server to compute the parameters of the query.
b. Polling table - Data can be refreshed using an Event Table. This is a table in the database which is populated with an entry recording the details of a table when that table is updated by the ETL process, the Analytics Server polls the table and purges data from the cache if a table has been updated. This is useful where incremental ETL processes are run during the day, for instance to update sales data, the frequency with which the Analytics Server checks the polling table can be set to coincide with that of the ETL so data from the more frequently updated tables is purged from the cache more often to avoid out of date results to queries. Where incremental ETL is run once a day or overnight for instance, this approach is arguably less beneficial. The frequency with which the Analytics Server polls the event table is set in the Analytics Administration tool, Tools>Utilities>Siebel Event Tables. N.B The parameters for the Event table contain table names only and cannot contain an alias, when the data for a table is purged data from an alias of that table is not, this can lead to misleading results and an alterative purging strategy must be found for the alias.
c. Table Level - In it’s simplest form, caching can be enabled table by table within the data warehouse, by default all tables have caching enabled and the persistence time, the time the data is left in the cache, is infinite. To achieve the best combination of performance improvement whilst limiting disk space used by the cache, tables that are rarely queried can be deselected from this process, performance can be further enhanced by altering the persistence time to coincide with incremental ETL processes as with method b. The two methods can also be used in conjunction with each other.
It is still important to purge the cache otherwise you can be querying yesterday’s data, even though an ETL was run overnight.
d. Manual Management – A cache manager is available from within the repository when you are connected in online mode. To access the Cache Manager select Tools\ Manage\ Cache. Note that this option is greyed out unless you have enabled caching in the NQSConfig.ini file. Manual cache management involves the purging of cache physically by a user. It is not suitable for day to day operations, but can be handy during testing.
Purging Options
Invoking ODBC Extension Functions
The following ODBC functions affect cache entries associated with the repository specified by the ODBC connection. You can call these functions using the nqcmd.exe command-line executable.
The syntax of the call will be as follows:
nqcmd -d "Analytics Web" –u administrator –p sadmin –s purge.txt
Where purge.txt contains the call (for example, call SAPurgeAllCache()).
SAPurgeCacheByQuery. Purges a cache entry that exactly matches a specified query.
The following call programmatically purges the cache entry associated with this query:
Call SAPurgeCacheByQuery(‘select lastname, firstname from employee where salary >
100000’ );
SAPurgeCacheByTable. Purges all cache entries associated with a specified physical table
name (fully qualified) for the repository to which the client has connected.
This function takes up to four parameters representing the four components (database, catalog,
schema and table name proper) of a fully qualified physical table name. For example, you might have a table with the fully qualified name of DBName.CatName.SchName.TabName. To purge the cache entries associated with this table in the physical layer of the Siebel Analytics repository, execute the following call in a script:
Call SAPurgeCacheByTable( ‘DBName’, ‘CatName’, ‘SchName’, ‘TabName’ );
Wild cards are not supported by the Siebel Analytics Server for this function. Additionally,
DBName and TabName cannot be null. If either one is null, you will receive an error message.
SAPurgeAllCache. Purges all cache entries. The following is an example of this call:
Call SAPurgeAllCache();
SAPurgeCacheByDatabase. Purges all cache entries associated with a specific physical
database name. A record is returned as a result of calling any of the ODBC procedures to purge
the cache. This function takes one parameter that represents the physical database name and
the parameter cannot be null. The following is an example of this call:
Call SAPurgeCacheByDatabase( ‘DBName’ );
Siebel Analytics Scheduler
The SA Scheduler can be used for running general purpose scripts that extend the functionality of Siebel Analytics.
The script purgeSASCache is used to periodically purge all of the cache from the Siebel Analytics Server:
/////////////////////////////////////////////////////////
// purgeSASCache.js
//
// Purges the cache on SAS.
// Parameter(0) - The user name to pass in to NQCMD.
// Parameter(1) - The password for the aforementioned user.
/////////////////////////////////////////////////////////
// The full path to nqcmd.exe
var nqCmd = "D:\\SiebelAnalytics\\Bin\\nqcmd.exe";
// The data source name
var dsn = "Analytics Web";
// The user to execute the queries
var user = Parameter(0);
// The password of the aforementioned user
var pswd = Parameter(1);
// The ODBC procedure call for purging the cache
var sqlStatement = "{call SAPurgeAllCache()};";
//////////////////////////////////////////////////////////
// Returns a string from the file name
//////////////////////////////////////////////////////////
function GetOutput(fso, fileName)
{
var outStream = fso.OpenTextFile(fileName, 1);
var output = outStream.ReadAll();
outStream.Close();
return output;
}
//////////////////////////////////////////////////////////
// Get WshShell object and run nqCmd. Capture the output
// so that we can handle erroneous conditions.
var wshShell = new ActiveXObject("WScript.Shell");
// Create a temp file to input the SQL statement.
var fso = new ActiveXObject("Scripting.FileSystemObject");
var tempFolder = fso.GetSpecialFolder(2);
var tempInFileName = fso.GetTempName();
var tempOutFileName = fso.GetTempName();
tempInFileName = tempFolder + "\\" + tempInFileName;
tempOutFileName = tempFolder + "\\" + tempOutFileName;
var tempInFile = fso.CreateTextFile(tempInFileName, true);
tempInFile.WriteLine(sqlStatement);
tempInFile.Close();
try
{
// execute
var dosCmd = nqCmd + " -d \"" + dsn + "\" -u \"" + user
+ "\" -p \"" + pswd + "\" -s \"" + tempInFileName + "\"" +
" -o \"" + tempOutFileName + "\"";
wshShell.Run(dosCmd, 0, true);
var output = GetOutput(fso, tempOutFileName);
// Remove the temp files
fso.DeleteFile(tempInFileName);
if (fso.FileExists(tempOutFileName)) {
fso.DeleteFile(tempOutFileName);
}
// Check the output for any errors
if (output.indexOf("Processed: 1 queries") == -1) {
ExitCode = -1;
Message = output;
}
else if (output.indexOf("Encountered") != -1) {
ExitCode = -2;
Message = output;
}
else {
ExitCode = 0;
}
} catch (e) {
if (fso.FileExists(tempInFileName)) {
fso.DeleteFile(tempInFileName);
}
if (fso.FileExists(tempOutFileName)) {
fso.DeleteFile(tempOutFileName);
}
throw e;
}
Options for Seeding the Cache
Seeding the cache can be automated via an ODBC call in much the same way as purging.
The syntax of the call will be as follows:
nqcmd -d "Analytics Web" –u administrator –p sadmin – file.sql
Where file sql is a script containing sql select statements to populate the cache, ideally these will be a super set of the queries issued by the requests in Siebel Answers and dashboards deemed most likely to derive maximum performance gains from using the cache.
Siebel Delivers can also be used to seed the cache automatically, the advantage of this is that iBots can trigger the specific requests that are required for caching, this should carry further performance benefits.
NQSConfig.ini
The NQSConfig.ini file located in the $SiebelAnalytics\Config folder needs to be modified in order to activate and parameterise Analytics Caching. Below are settings for caching with cache tables of an expected size of approximately 250 000 records.
Parameter Value Comments
ENABLE
YES
Turns overall Caching on or off
DATA_STORAGE_PATHS
“C:\SiebelAnalyticsData\Temp\Cache 500 MB”
For optimal performance, the directories specified should be on high performance storage systems.
METADATA_FILE
"C:\SiebelAnalytics\metadata_file.dat"
The filename needs to be a fully qualified pathname with a .dat extension.
REPLACE_ALGORITHM
LRU
Currently, the only supported algorithm is LRU (Least Recently Used).
BUFFER_POOL_SIZE
20 MB
Specifies the amount of physical memory Analytics can use to store Cache files, in. More cache in memory means better response time.
MAX_ROWS_PER_CACHE_ENTRY
0
When set to 0, there is no limit to the number of rows per cache entry.
MAX_CACHE_ENTRY_SIZE
10 MB
Maximum size of a specific cache entry on the Physical drive.
POPULATE_AGGREGATE_ROLLUP_HITS
YES
Specifies whether aggregate cache files should be created. Setting this parameter to TRUE may result in better performance, but results in more entries being added to the cache.
METADATA_BACKUP_FREQUENCY_MINUTES
1440
This creates a backup file with a .bak extension. There will only ever be one of these.
Hope this helps
Monday, September 18, 2006
Three sheets to the wind
No, not a description of the weekend’s activities unfortunately, not a drop passed my lips.
The sheets to which I refer are CSS or Cascading Style Sheets, PortalBanner.css, PortalContent.css and Views.css.
You probably will not be interested to know that the original form of the expression was 'three sheets in the wind', this refers to the nautical term for a rope, derived from sheet line, a rope used to control a sheet or sail, and literally means 'with the sail completely unsecured', and thus flapping about, and with the boat itself thus unsteady. So, no more grog at lunch time.
Style sheets are used to separate the content of an HTML page from the control and formatting applied, this is particularly useful where the content, i.e. the data, is more important than the appearance in the long term.
From a productivity point of view, creating the 'look' of your dash boards once leaves you more time to actually create the reports.
In early HTML pages the appearance of text was controlled by tags like 'FONT' and their attributes like color, face, size etc, these were used to surround the text to which they were applied, this was fine until you had a hundred pages using three colours of text and you decided to change the colour, the tag for every instance of the text had to be changed. With 'css' the tag becomes a reference to the style sheet, and therefore, if you wish to change the attributes of the tag you change them once, in the style sheet, not on every page.
PortalBanner and PortalContent are css files that affect Siebel Dashboards, they can be found in SiebelAnalytics\Web\App\Res\s_Siebel77\b_mozilla_4, a word of warning however, the best way to learn what does what is to 'do a Claudio', i.e. tinker all you like to see what happens.
With this in mind you should always copy the original before you start to tinker, likewise, if you decide to use an edited css file, save a copy to the SiebelAnalyticsData\Web\App\Res directory to preserve a copy should you ever upgrade analytics.
Siebel's recommended practice is to copy the s_Siebel77 folder to the SiebelAnalyticsData folder and then rename it appropriately, this file name is then available as a style to select in Dashboard Properties, once the Analytics Web service has been restarted.
Editing these can be a useful way to enhance the appearance of a dashboard and make it more familiar to the users by using a corporate colour scheme, for instance. You should also remember that there are contractual obligations with regard to the appearance of elements such as the 'Powered by Siebel' logo etc.
To my mind though, the most useful of the three files is Views.css, this is the file that controls the appearance of the reports created in Answers and displayed in your dashboards, the reason I say this is because the sheer volume of reports means that altering these settings once will save you the most time, even using the copy formatting feature will not save you as much time.
The styles are defined as classes (name preceded by a full stop) under headings commented out e.g. '/* Title */' .TitleCell, the attributes are then defined within the curly brackets, names such as these are fairly intuitive, some are more obscure and you might only decipher them by tinkering. I have found the most useful to be:
.TitleTable The border attributes control the heavy line below a report title, change the colour to suit your corporate image.
.TitleCell The title added to the report via the table properties.
.TitleNameCell This formats the title if the saved report name is used.
Also useful for the table of results it self:
.ResultsTable The outer borders of the results table.
.ResultsTable TD Individual table cells of the results table.
.ColumnHdg Column heading format.
.ColumnHdgD Column heading where the heading is a drill down.
And so on,
I hope this has wetted your appetite, happy tinkering.
Thursday, September 14, 2006
Do you feel insecure?
Security. Love it or loathe it? Most of the time the choice is yours, you can choose not to lock your house or car, you can choose not to fly, you can choose to keep your PIN in your phone memory under PIN, what you probably can't choose is whether or not to apply it to your Analytics system, because some one else has made that decision for you and they pay your salary!
A brief scan of the popular analytics message boards does suggest that this is part of the system a good number of people can't get their heads round, so I thought I'd jot a few of my thoughts on the subject.
Within Siebel Analytics there are two basic types of security, Data Level and Object Level.
Actually, there are EIGHT layers of security in an Integrated Analytics application (can you identify them all?).
Data level is about controlling the data i.e. the facts that a user can see, typically this is because managers don't want fisticuffs in the office; so preventing everyone from seeing how much commission the sales team get is generally a good idea. Also, you may be familiar with TMI, Too Much Information, if like me you're a nosey parker than everyone else's data is far more interesting than your own and you can't resist having a look should the opportunity present its self. Giving all your staff this opportunity can have a dramatic effect on productivity.
On a serious note in the financial markets you'll know all about 'chinese walls' and the need to keep data secret.
At the simplest level, this is how to go about administering data level security;
PS. The eight layers...
A brief scan of the popular analytics message boards does suggest that this is part of the system a good number of people can't get their heads round, so I thought I'd jot a few of my thoughts on the subject.
Within Siebel Analytics there are two basic types of security, Data Level and Object Level.
Actually, there are EIGHT layers of security in an Integrated Analytics application (can you identify them all?).
Data level is about controlling the data i.e. the facts that a user can see, typically this is because managers don't want fisticuffs in the office; so preventing everyone from seeing how much commission the sales team get is generally a good idea. Also, you may be familiar with TMI, Too Much Information, if like me you're a nosey parker than everyone else's data is far more interesting than your own and you can't resist having a look should the opportunity present its self. Giving all your staff this opportunity can have a dramatic effect on productivity.
On a serious note in the financial markets you'll know all about 'chinese walls' and the need to keep data secret.
At the simplest level, this is how to go about administering data level security;
- In the Analytics Administration Tool go to Manage>Security to open the Security Manager, the security objects are displayed down the left,
- Click on Groups and then right click in the r.hand pane and,
- Select New Security Group, the procedure is the same for adding a new user.
At this point you should already have thought about whether you are going to administer security at group level or individual level, this will be largely dictated by the number of users, again it is probably not your decision to make so I hope the chiefs in your organisation know what they are on about!
So, for example you have created a group called Agents, these could be support staff or telesales, it doesn't really matter, the point is you want to limit their view of the data to those applicable to their geographical region of responsibility. In the right hand pane double click the Agents group, and click the permissions button and select the Filters tab, now click the Add button to add an object (i.e. table) whose content (data) you wish to restrict access to, highlight the table and click Select, now check that the Status is set to Enable and click the Ellipsis button to open the Expression Builder, the world is now your SQL oyster and you can do pretty much what you want to restrict the view of the data available from your chosen table, and like oysters, SQL should be chosen with care to avoid indigestion!
The choice with this type of filter is between hard coding a value, so the filter will always filter the same value, this will seem like a bad idea if the data is changed, for instance if the Regions are renamed at some time in the future. A better solution is to use a variable that returns the values available for the specific user or group at the time of logging in.
Anyway, it's late and there's so much more to this subject that I will deliver it in small bite sized chunks.
To be continued ......PS. The eight layers...
- Application Log in (Application Authentication)
- Responsibilty to a View
- Access to Analytics system (Analytics Authentication)
- Access to Analytics Components (privileges)
- Rights to Webcat object (e.g. Particular Dashboard, Report, Folder)
- Rights to Analytics Repository Object (Usually set on Presentation Layer)
- Data Restrictions (via Security )
- Database Access (normally uses shared name in connection pool)
Wednesday, September 06, 2006
DAc days
Question. How do you load 80 million records into the Data warehouse?
Answer. Slowly!
As we are now in version 7.8 of the CRM application there is lots of work around upgrading from previous versions. Normally an upgrade of the data warehouse will provide companies with an opportunity to reassess what is captured and how. The biggest dilemma is the choice between a simple upgrade and a fresh installation.
Both methods have their benefits, but for the developers the most interesting choice is to go for a new fresh installation. No need to learn how the previous guys worked their magic, and no constraints of the old data structures, ETL, etc.
Whichever method you adopt there will always be data migration. If you’re lucky there is not a big gap between versions and the data structures are similar; the system has only been used for a year and only has a few million records (and pigs might fly too!).
One project I have been involved had approximately 150 M records in the legacy CRM system. After a year of hard labour this data was converted to 80 M fresh rows and was loaded into the new eBusiness application. This is where we come in. The new data warehouse was designed and built around the 7.8.4 database with no vertical licences. (more on this subject another day).
The standard Informatica routines and DAC repository is the basis of the new ETL. The ‘opportunity’ in the design phase was fact that there were approx 150 custom fields added to various S_ tables. (more on this another day!)
So, here we are with a new blank database, customised ETL system and 80 M records ready to load. If you were using the standard DAC then you would now run the execution plan ‘Complete ETL’. Sit back and wait a few days. But what about the database? Is it big enough? Have you created the correct tablespaces, and are these reflected in the DAC? (where you may ask – hint: look at the Indices)
So half way through day one, and the db has crashed four times due to lack of tablespace. After various calls to the dba you’re back up and running again. Midnight of day one and a standard virus protection system kicks in. Server dies under the weight of workload. Morning of day three and the team are bleery eyed and living on extra strong expresso, having spent the night coaxing the DAC into life, time and time again. This time due to centrally organised Server updates (a Windows Patch here, a java update there). Day five and the testers arrive to start picking holes in the results; you know the sort of thing, table W_xxx has no data, Field xx_Type has the wrong LOV’s in.
Fixes were made and the following weekend set aside to do a full load again. Reset the warehouse; purge the run details, analyse the tables; stop the virus protection, disable the PC updates, increase the tablespace and cross your fingers. From Friday night to Sunday morning all is well
Luckily for us the above is just a nightmare that we usually avoid due to good planning, lots of luck, and plenty of time to be prepared.
You have been warned.
*For opportunity normally substitute ‘Problem’!
Answer. Slowly!
As we are now in version 7.8 of the CRM application there is lots of work around upgrading from previous versions. Normally an upgrade of the data warehouse will provide companies with an opportunity to reassess what is captured and how. The biggest dilemma is the choice between a simple upgrade and a fresh installation.
Both methods have their benefits, but for the developers the most interesting choice is to go for a new fresh installation. No need to learn how the previous guys worked their magic, and no constraints of the old data structures, ETL, etc.
Whichever method you adopt there will always be data migration. If you’re lucky there is not a big gap between versions and the data structures are similar; the system has only been used for a year and only has a few million records (and pigs might fly too!).
One project I have been involved had approximately 150 M records in the legacy CRM system. After a year of hard labour this data was converted to 80 M fresh rows and was loaded into the new eBusiness application. This is where we come in. The new data warehouse was designed and built around the 7.8.4 database with no vertical licences. (more on this subject another day).
The standard Informatica routines and DAC repository is the basis of the new ETL. The ‘opportunity’ in the design phase was fact that there were approx 150 custom fields added to various S_ tables. (more on this another day!)
So, here we are with a new blank database, customised ETL system and 80 M records ready to load. If you were using the standard DAC then you would now run the execution plan ‘Complete ETL’. Sit back and wait a few days. But what about the database? Is it big enough? Have you created the correct tablespaces, and are these reflected in the DAC? (where you may ask – hint: look at the Indices)
So half way through day one, and the db has crashed four times due to lack of tablespace. After various calls to the dba you’re back up and running again. Midnight of day one and a standard virus protection system kicks in. Server dies under the weight of workload. Morning of day three and the team are bleery eyed and living on extra strong expresso, having spent the night coaxing the DAC into life, time and time again. This time due to centrally organised Server updates (a Windows Patch here, a java update there). Day five and the testers arrive to start picking holes in the results; you know the sort of thing, table W_xxx has no data, Field xx_Type has the wrong LOV’s in.
Fixes were made and the following weekend set aside to do a full load again. Reset the warehouse; purge the run details, analyse the tables; stop the virus protection, disable the PC updates, increase the tablespace and cross your fingers. From Friday night to Sunday morning all is well
Luckily for us the above is just a nightmare that we usually avoid due to good planning, lots of luck, and plenty of time to be prepared.
You have been warned.
*For opportunity normally substitute ‘Problem’!
Thursday, August 31, 2006
A quick note on Narratives
Narratives are very useful to give user information in a readable format. Some data is not easy to name so a more descriptive comment can be used instead of jus the column name
Consider:
Run Date
24/08/06
What does this mean?
You could use:
‘The date when the latest ETL was run is: 24 Aug 2006’
Obviously the more descriptive version in unusable as a column heading, therefore use a Narrative.
The narrative is a type of view that you add to a request. The formatting options are restricted to bold, italics and underline but you can play with the colours.
To produce the result above you would fill the main section (not the header and footer section) with the following
The date when the latest ETL was run is: [b]@1[/b]
Where [b] to make bold and @1 relates to field number one.
Placed on the top or bottom of a dashboard these narratives provide some unobtrusive feedback to the users. I normally build a dashboard which has repository variables displayed, and often put the Version Number variable onto a general tab.
told you it was a quick note!
Consider:
Run Date
24/08/06
What does this mean?
You could use:
‘The date when the latest ETL was run is: 24 Aug 2006’
Obviously the more descriptive version in unusable as a column heading, therefore use a Narrative.
The narrative is a type of view that you add to a request. The formatting options are restricted to bold, italics and underline but you can play with the colours.
To produce the result above you would fill the main section (not the header and footer section) with the following
The date when the latest ETL was run is: [b]@1[/b]
Where [b] to make bold and @1 relates to field number one.
Placed on the top or bottom of a dashboard these narratives provide some unobtrusive feedback to the users. I normally build a dashboard which has repository variables displayed, and often put the Version Number variable onto a general tab.
told you it was a quick note!
A slow day at the Coal Face
August 31st
Today is a slow day. The database is down due to constant ORA-03113 errors, and sometimes 12152 errors. I don’t know what they are but it means we get to work late nights and weekends til the end of the project. If any of you know what these errors are I’m sure the DBA’s would love to know!
As it is so slow I thought I’d list my favourite words of wisdom and other such irrelevant things
It is far more impressive when others discover your good qualities without your help.
Projects
Today is a slow day. The database is down due to constant ORA-03113 errors, and sometimes 12152 errors. I don’t know what they are but it means we get to work late nights and weekends til the end of the project. If any of you know what these errors are I’m sure the DBA’s would love to know!
As it is so slow I thought I’d list my favourite words of wisdom and other such irrelevant things
It is far more impressive when others discover your good qualities without your help.
Projects
Rome did not create a great empire by having meetings; they did it by killing all those who opposed them.
If you can stay calm, while all around you is chaos...then you probably haven't completely understood the seriousness of the situation.
A person who smiles in the face of adversity...probably has a scapegoat.
TEAMWORK...means never having to take all the blame yourself.
Never underestimate the power of very stupid people in large groups.
Succeed in spite of management.
Advice
- Never test the depth of the water with both feet.
- It may be that your sole purpose in life is simply to serve as a warning to others.
- If you think nobody cares if you're alive, try missing a couple of car payments.
- If you lend someone $20, and never see that person again; it was probably worth it.
- If you haven't much education you must use your brain.
- Who gossips to you will gossip of you.
- When someone says, "Do you want my opinion?" - it's always a negative one.
- When someone is having a bad day, be silent, sit close by and nuzzle them gently.
- Doing a job RIGHT the first time gets the job done. Doing the job WRONG fourteen times gives you job security.
Wisdom
He Who Laughs Last Thinks Slowest
Wherever you go; there you are
Cynics
- This isn't an office. It's Hell with fluorescent lighting.
- I pretend to work. They pretend to pay me.
- Sarcasm is just one more service we offer.
- Errors have been made. Others will be blamed.
- A cubicle is just a padded cell without a door.
- Can I trade this job for what's behind door 1?
- I thought I wanted a career, turns out I just wanted paychecks.
- Chaos, panic, & disorder - my work here is done.
- No one is listening until you make a mistake.
- I Haven't Lost My Mind - It's Backed Up On Disk Somewhere
- Aim Low; Reach Your Goals; Avoid Disappointment.
Wednesday, August 23, 2006
My First Blog
Please be gentle with me!
I am a complete blogging numptie, but I just had to give it a try.
I will mainly be talking about my experience with Analytics ( ex of Siebel now with Oracle), plus a little about my passion for sailing.
Let me know you're here reading my stuff and what you do.
I expect to write one article per week and will always be available to take your email mesages.
Adrian
adrian.ward@majendi.com
I am a complete blogging numptie, but I just had to give it a try.
I will mainly be talking about my experience with Analytics ( ex of Siebel now with Oracle), plus a little about my passion for sailing.
Let me know you're here reading my stuff and what you do.
I expect to write one article per week and will always be available to take your email mesages.
Adrian
adrian.ward@majendi.com
Subscribe to:
Posts (Atom)
The Cowes

Cowes Racing


{kind=link}